2.3 - Le traitement
2.3.1 Etablir des tableaux de résultats
- Le premier traitement est la plupart du temps mené par l'organisme chargé de l'étude. Mais il peut s'avérer utile pour le gestionnaire d'avoir à l'esprit les formes de traitement possibles, ne serait-ce qu'en raison de la possibilité qui lui est laissée de compléter les traitements en fonction de besoins qui lui sont propres.
2.3.1.1 Elaborer le plan de tri
- Ce plan est également de la responsabilité de l'organisme chargé du traitement. Il peut être utile de l'élaborer en commun. Il précise les différents tris souhaités en 2 ou 3 vagues: on commence en général par les tris à plat puis on élabore des tris croisés à commencer par les plus simples (par exemple les tranches d'âge ou les CSP avec les pratiques ou les attentes). On pourra affiner les tris au fur et à mesure des différentes vagues. Il importe de ne pas se perdre dans un nombre trop important de tris: ne traiter que les tris les plus significatifs, ceux qui parlent à l'intuition, ceux qui décrivent des grandes masses en gardant à l'esprit une taille de population résiduelles (quelle sera l'utilité d'un tri qui définit des sous-populations marginales ?)
2.3.1.2 A partir des tris " à plat "
- Le premier traitement doit s'effectuer à partir des données brutes. L'idéal en la matière semble être le report systématique des résultats bruts (en pourcentage et en effectif) à même le questionnaire. L'intérêt est évident: une visualisation immédiate de l'essentiel des données. Ce type de traitement permet bien souvent de détecter les résultats incongrus qu'il faudra " éliminer" ou en tous cas analyser à part.
- Il est par ailleurs toujours " agréable" de pouvoir visualiser les données. On n'hésitera pas à avoir recours aux schémas (histogrammes, graphiques à secteurs, courbes, etc.). Ces graphiques devront toujours être accompagnés d'une légende. Dans chaque cas, les bases numériques et la population de référence devront systématiquement être rappelées.
2.3.1.3 A partir des tris croisés 
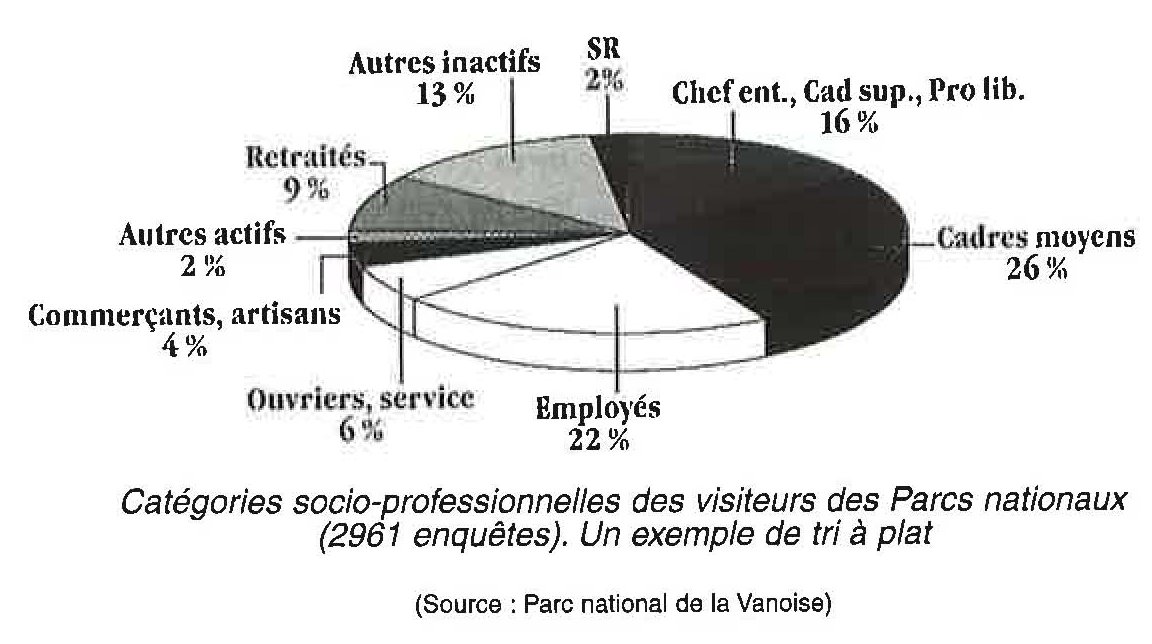
- Le recours aux tris croisés (croisement d'une variable par une autre) fait également partie des « incontournables ". Il faut veiller à ne croiser que ce qui présente un sens et en tout état de cause ne pas croiser à outrance mais au contraire sélectionner a priori les tris pertinents pour l'analyse.
2.3.1.4 Veiller à travailler sur des chiffres significatifs
- Quels que soient les tris réalisés, il est indispensable de veiller à obtenir une population de référence qui soit suffisante pour obtenir des sous-populations dont le nombre reste significatif. Par exemple, si l'on doit obtenir 4 sous-populations numériquement équivalentes, la population de départ doit être au moins de 200 personnes pour obtenir in fine des sous-populations de 50 personnes (50 étant un minimum).
- De même, on veillera à respecter les intervalles de confiance et les écarts significatifs entre pourcentages (selon abaque statistique).
- L'intervalle de confiance détermine la précision d'un pourcentage en fonction de la taille de l'échantillon. Par exemple pour une précision à 95.45% près, pour un échantillon de 200 personnes, si un résultat porte sur 20% des personnes interrogées, l'intervalle de confiance déterminé par l'abaque est de 5.7%, ce qui veut dire que, pour être correctement interprété, le résultat est, en fait, compris entre 14.3% et 25.7%.
- L'écart significatif entre pourcentages, selon une abaque stastique, permet de comparer des résultats obtenus sur des échantillons de taille différentes. Exemple de question: 75% des visiteurs du site A, dont l'échantillon interrogé est de 200 personnes, considèrent que les parkings peuvent être payants, contre 65% des visiteurs du site B dont l'échantillon est de 300 personnes. L'écart entre les deux sites (10%) est-il significatif ? L'abaque montre que l'écart significatif minimum est de 8% : la réponse est donc positive.
2.3.2 Les méthodes descriptives
- Une fois établis les tableaux de résultats, il peut dans certains cas s'avérer intéressant d'avoir recours à des méthodes dites « descriptives » . Il s'agit principalement pour la présente étude de l'analyse factorielle et de la typologie.
- L'analyse factorielle consiste à résumer l'information contenue dans un tableau de chiffres individus/ variables, en remplaçant les variables initiales par un nombre plus petit de variables composites ou facteurs. Par exemple, supposons que 40 variables d'attitude ont été mesurées sur 800 visiteurs. Faut-il vraiment garder les 32 000 valeurs obtenues ou n'est-il pas possible de résumer toute cette information par une, deux ou trois variables de synthèse? Ce résumé des données initiales (sous forme de mappings) peut alors être utilisé pour faciliter une interprétation portant sur un nombre plus restreint de variables. La présentation graphique facilite souvent l'analyse par déduction du contenu des axes structurants.

- La typologie part du problème suivant: étant donné un ensemble d'individus décrits par un certain nombre de caractéristiques (variables), constituer des groupes (types) d'individus tels que les individus soient les plus similaires possibles au sein d'un groupe et que les groupes soient aussi dissemblables possibles; la ressemblance ou la dissemblance étant mesurée sur l'ensemble des variables décrivant les individus.
Dans les deux cas, le recours à un logiciel adapté est nécessaire.
2.3.3 Calcul des ratios
- Un certain nombre de ratios, définis au préalable, devront être calculés. Il s'agit par exemple de ratios voitures/visiteurs, visiteurs/randonneurs. En tout état de cause, il importe de normer ce calcul c'està- dire, en d'autres termes, de reconduire d'une enquête sur l'autre le calcul de ces ratios, quitte à en ajouter d'autres, jugés désormais pertinents. Voir p 40 les calculs de ratio utilisés dans l'enquête 1996 par les Parcs nationaux des Ecrins, de la Vanoise et des Pyrénées. Le choix des ratios est directement lié aux objectifs de l'étude et aux résultats attendus, il représente une forme d'exploitation de l'enquête prévue dès l'élaboration du cahier des charges de celle-ci.
- Deux exemples de calcul de ration
- calcul 1: nombre de visiteurs sur un site
On appellera visiteur la personne accédant au site en voiture.
D est la durée (jour, semaine, mois, saison, année) pour laquelle l'estimation est recherchée. Du fait des décalages entre le moment du comptage et l'arrivée sur le site, D ne peut être inférieur à la journée (sauf si ce décalage est connu et faible).
T est le trafic routier pendant le temps D sur l'itinérarire accédant au site (en général les données fournies par les compteurs routiers totalisent le trafic dans les deux sens).
P est le nombre moyen de passagers par véhicules (obtenu par sondage sur les véhicules accédant au site).
V est le nombre de personnes ayant visité un site pendant le temps D.
| V/D (visiteurs par unité de temps) = P x T/2 |
- calcul 2 : nombre de randonneurs ou promeneurs sur un site
On appellera randonneur toute personne visitant un site naturel et s'éloignant de son véhicule d'au moins un quart d'heure de marche.
D et T tels que définis dans l'exemple de calcul 1
T est le trafic routier pendant le temps D sur l'itinéraire accédant au site (en général les données fournies par les compteurs routiers totalisent le trafic dans les deux sens).
R est le nombre de randonneurs (ou promeneurs) ayant fréquenté le site pendant le temps D
d est la durée du comptage sur le sentier
r est le nombre de randonneurs comptés sur le sentier pendant le temps d, dans les deux sens (aller et retour)
t est le trafic routier enregistré pendant le temps d (dans les deux sens) sur la route d'accès au site
n est le nombre de comptages effectués sur le sentier
Q est le rapport calculé entre le trafic pédestre (r) et le trafic routier (t) : Q=r/t
Qn est le rapport rit calculé pour le comptage n
R/D (nombre de randonneurs par unité de temps) est le rapport Q moyen multiplié par le trafic
| R/D = [(∑:Qn)/n] x T |
2.3.4 La comparaison avec les enquêtes antérieures
- Il est évidemment fondamental de suivre les évolutions d'une enquête à l'autre, ne serait-ce que pour construire ensuite des courbes permettant des projections dans le futur. L'utilisation des séries chronologiques peut s'avérer ici très utile. Il nécessite d'avoir recours à un statisticien.
- Plus simplement, on devra établir des tableaux et schémas de comparaison sur certaines variables clé.
- Dans les deux cas, il y a nécessité d'une stabilité des approches pour que les rapprochements et comparaisons soient possibles et fiables statistiquement (systèmes de comptages, sites étudiés, formes des questions, etc.).
2.3.5 Principes de différenciation
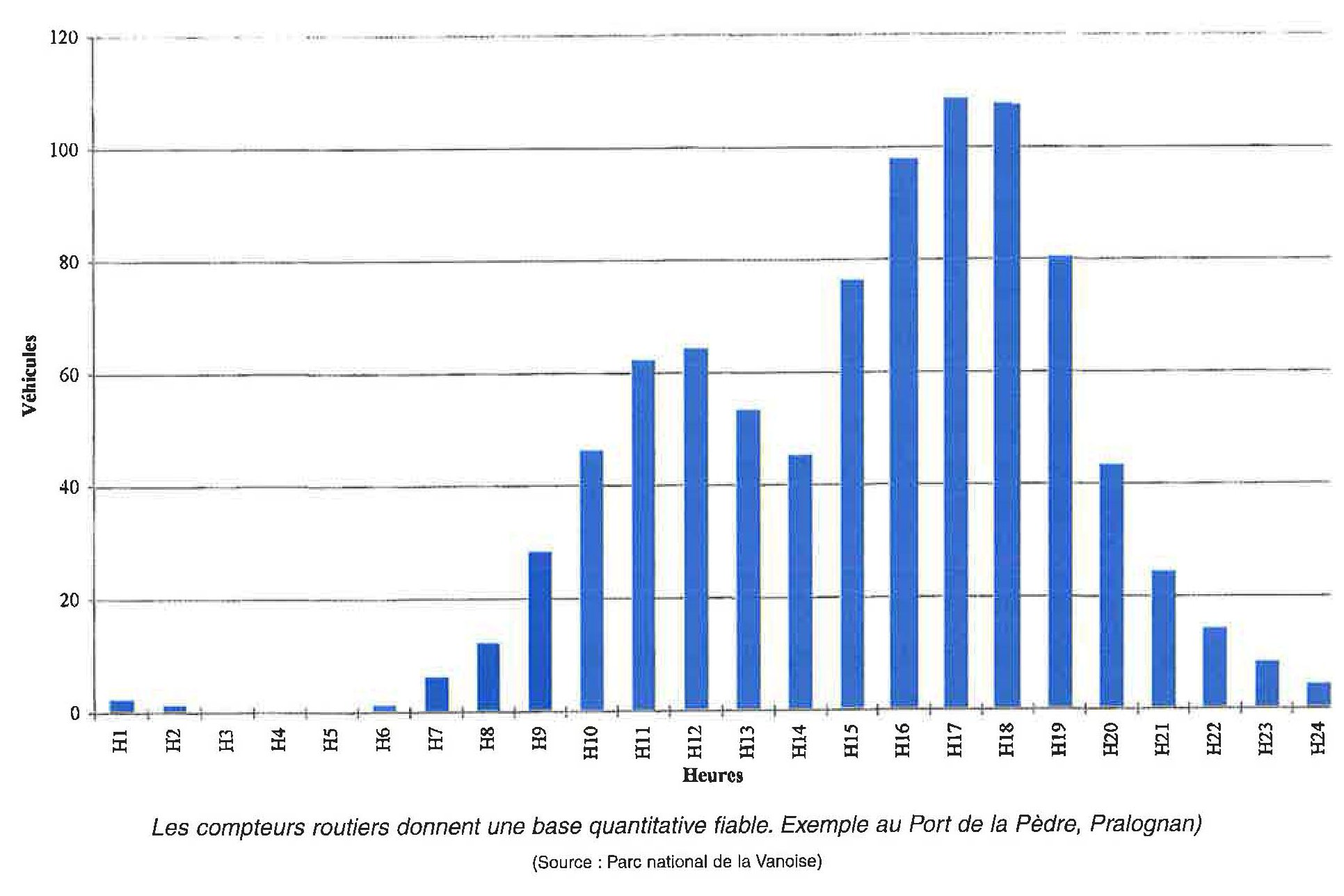
- Les relevés quotidiens des passages routiers forment des séries de données chronologiques représentatives de la période estivale.
- Pour tirer les renseignements majeurs contenus dans ces données et pouvoir comparer différentes séries (d'un lieu à un autre, d'une enquête à un autre), on peut procéder :
- à un lissage des données afin de dégager l'allure générale de la fréquentation (élimination partielle des fluctuations mineures) par la méthode des moyennes mobiles ;
- à une « mesure » de l'orientation et des fluctuations des grandes tendances de la fréquentation estivale - croissance, décroissance (ajustement des fonctions par la méthode des moindres carrés).

- Lors de la réalisation d'interprétation de synthèses d'enquêtes réalisées sur plusieurs sites, les données sur la fréquentation relative de chacun permet de pondérer les enquêtes.
- Par exemple : supposons trois sites
| site n° 1 | 2 000 visiteurs = v1 | 50 enquêtes effectuées = n1 |
| site n° 2 | 1 000 visiteu rs = v2 | 50 enquêtes effectuées = n2 |
| site n° 3 | 500 visiteurs = v3 | 25 enquêtes effectuées = n3 |
Les coefficients de correction à affecter aux différents résultats pour qu'ils soient significatifs sont :
| site n° 1 | c1 = 1 |
| site n° 2 | c2 = v2/v1 x n2/n1 = 0.5 |
| site n° 3 | c3 = v3/v1 x n3/n1 = 0.5 |
Les résultats des enquêtes sur les sites n02 et n03 devront compter pour moitié par rapport aux enquêtes effectuées sur le site n01. Une autre façon de prendre en compte l'intensité de la fréquentation sur les résultats des questionnaires est d'adapter le nombre de questionnaires fait sur un site à sa fréquentation relative (pour 100 Q en site n° 1 il faut faire 50 Q au site n02 et 25 Q au site n03), Ceci suppose de connaître a priori la fréquentation des sites.
2.3.6 Des questions importantes à résoudre
- Lors du traitement des comptages, le gestionnaire doit avoir à l'esprit qu'il aura à répondre à un certain nombre de questions parmi lesquelles :
- Comment estimer la fréquentation sur les sentiers sans comptage ?
- Comment réduire l'écart entre les sentiers comptés et les sentiers estimés (fiabilité des estimations) ?
- Comment répartir les flux au delà des points de comptage ?
- Comment projeter les données (volume, tendances, pics) ?
- Comment intégrer les données externes (statistiques du tourisme, SNCF, comptages autoroutiers, DDE) ?
- Certaines questions auront déjà reçu des réponses dans les enquêtes précédentes. Il est important de ne pas réinventer des ratios ou des méthodes à chaque enquête (si le travail a déjà été réalisé avec succès auparavant), sous peine de perdre en continuité.
- On peut peaufiner l'outil mais ne pas le bouleverser (sauf changement d'environnement majeur).
- Enfin, le gestionnaire doit avoir une attitude prudente dans son analyse des données (celle-ci pouvant avoir des effets important sur les décisions) et de manière générale :
- Eliminer des informations dont la validité est douteuse.
- Veiller lors des tris croisés à conserver des effectifs suffisants. • Utiliser des indicateurs différents pour valider certains résultats.
- Ne comparer que ce qui est strictement comparable.